単 回帰 分析 重 回帰 分析
- 単回帰分析の結果の見方(エクセルのデータ分析ツール)【回帰分析シリーズ2】 | 業務改善+ITコンサルティング、econoshift
- 重回帰分析と分散分析、結局は何が違うのでしょうか…? - 講義で分析につい... - Yahoo!知恵袋
- 単回帰分析 重回帰分析 わかりやすく
- Rで線形回帰分析(重回帰・単回帰) | 獣医 x プログラミング
- 単回帰分析と重回帰分析を丁寧に解説 | デジマール株式会社|デジタルマーケティングエージェンシー
5*sd_y); target += normal_lpdf(b[1+i] | 0, 2. 5*sd_y/sd_x[i]);} target += exponential_lpdf(sigma | 1/sd_y);} generated quantities { vector[N] log_lik; vector[N] y_pred; log_lik[n] = lognormal_lpdf(Y[n] | mu[n], sigma); y_pred[n] = lognormal_rng(mu[n], sigma);}} 結果・モデル比較 モデル 回帰係数 平均値 95%信頼区間 正規分布 打率 94333. 51 [39196. 45~147364. 60] 対数正規分布 129314. 2 [1422. 257~10638606] 本塁打 585. 29 [418. 26~752. 90] 1. 04 [1. 03~1. 06] 盗塁 97. 52 [-109. 85~300. 37] 1. 01 [0. 99~1. 03] 正規分布モデルと比べて、対数正規分布モデルの方は打率の95%信頼区間が範囲が広くなりすぎてしまい、本塁打や盗塁の効果がほとんどなくなってしまいました。打率1割で最大100億円….. 追記:対数正規モデルの結果はexp()で変換した値になります。 左:正規分布、右:対数正規分布 事後予測チェックの一貫として、今回のモデルから発生させた乱数をbayesplot::ppc_dens_overlay関数を使って描画してみました。どうやら対数正規分布の方が重なりは良さそうですね。実践が今回のデータ、色の薄い線が今回のモデルから発生させ乱数です。 モデル比較 WAIC 2696. 2735 2546. 0573 自由エネルギー 1357. 456 1294. 289 WAICと自由エネルギーを計算してみた所、対数正規分布モデルの方がどちらも低くなりました。 いかがでし(ry 今回は交絡しなさそうな変数として、打率・本塁打・盗塁数をチョイスしてみました。対数正規分布モデルは、情報量規準では良かったものの、打率の95%信頼区間が広くなってしまいました。野球の指標はたくさんあるので、対数正規分布モデルをベースに変数選択など、モデルの改善の余地はありそうです。 参考文献 Gelman et al.
単回帰分析の結果の見方(エクセルのデータ分析ツール)【回帰分析シリーズ2】 | 業務改善+ITコンサルティング、econoshift
- Efficient wma mp3 converter 日本 語 化 パッチ
- 日本 臨床 栄養 代謝 学会
- 統計分析の基礎「単回帰分析」についての理解【その3】 – カジノ攻略
- 楽天証券 指値注文 やり方 米etf
- 『ウソツキ!ゴクオーくん 16巻』|感想・レビュー・試し読み - 読書メーター
- ひとり じゃ ない から b o o
- 回帰分析とは|意味・例・Excel、R、Pythonそれぞれでの分析方法を紹介 | Ledge.ai
- 今日からはじめるExcelデータ分析!第3回~回帰分析で結果を予測してみよう~ | Winスクールお役立ち情報 | 仕事と資格に強いパソコン教室。全国展開
- がん消滅の罠~完全寛解の謎~ネタバレと感想 キャスティングが豪華で面白かった! - ミステリーその他
重回帰分析と分散分析、結局は何が違うのでしょうか…? - 講義で分析につい... - Yahoo!知恵袋
単回帰分析 重回帰分析 わかりやすく
この記事を書いている人 - WRITER - 何かの現象を引き起こす要因を同定するために、候補となる要因を複数リストアップして、多変量回帰分析を行い、どの要因が最も寄与が大きいかを調べるということが良く行われます。その際、多変量回帰分析の前に、個々の要因(独立変数)に関してまず単変量回帰分析を行うという記述を良く見かけます。そのあたりの統計解析の実際的な手順について情報をまとめておきます。 疑問:多変量の前にまず単変量? 多変量解析をするのなら、わざわざ単変量で個別に解析する必要はないのでは?と思ったのですが、同じような疑問を持つ人が多いようです。 ある病気の予後に関して関係があると予想した因子A, B, C, D, E, Fに関して単変量解析をしたら、A, B, Cが有意と考えられた場合、次に多変量解析を行う場合は、A, B, C, D, E, Fのすべての因子で解析して判断すべきでしょうか?それとも関連がありそうなA, B, Cによるモデルで解析するべきでしょうか? ( 教えて!goo 2009年 ) 上司 の発表スライドなどを参考に解析をしております。その中に、 単変量解析をしたうえで、そのP値を参考に多変量解析 に組み込んで解析しているスライドがあり、そういうものなのかと考えておりました。ただ、ネットで調べますと、それは 解析ツールが未発達な時代の方法 であり、今は 共変量をしぼらず多変量解析に組み込む のが正しいという記述も散見されました。( YAHOO! JAPAN知恵袋 2020年) 多変量解析の手順:いきなり多変量はやらない? 多変量解析は、多くの要素の相互関連を分析できますが、 最初から多くの要素を一度に分析するわけではありません 。下図のように、 まずは単変量解析や2変量解析 で データの特徴を掴んで 、それから多変量解析を実施するのが基本です。(多変量解析とは?入門者にも理解しやすい手順や具体的な手法をわかりやすく解説 Udemy 2019年 ) 単変量解析、2変量解析を経て、多変量解析に 進みます。多変量解析の結果が思わしくない場合、 単変量解析に戻って、再度2変量解析、多変量解析に 進むこともあります。( Albert Data Analysis ) 多変量解析の手順:本当にいきなり多変量はやらないの? 正しい方法 は、 先行研究の知見や臨床的判断 に基づき、被説明変数との 関連性が臨床的に示唆される説明変数をできるだけ多く強制投入 するやり方です。… 重要な説明変数のデータが入手できない場合、正しいモデルを設定することはできない ので、注意が必要です。アウトカムに影響を及ぼしそうな要因に関して、先行研究を含めて予備的な知見がない場合や不足している場合、 次善の策 として、網羅的に収集されたデータから 単変量回帰である程度有意(P<0.
Rで線形回帰分析(重回帰・単回帰) | 獣医 x プログラミング
直径(cm) 値段(円) 1 12 700 2 16 900 3 20 1300 4 28 1750 5 36 1800 今回はピザの直径を使って、値段を予測します。 では、始めにデータを入力します。 x = [ [ 12], [ 16], [ 20], [ 28], [ 36]] y = [ [ 700], [ 900], [ 1300], [ 1750], [ 1800]] 次にこのデータがどのようになっているのか、回帰をする必要があるかなどmatplotlibをつかって可視化してみましょう。 1 2 3 4 5 6 7 8 9 10 11 12 13 14 import matplotlib. pyplot as plt # テキストエディタで実行する場合はこの行をコメントアウト(コメント化)してください。% matplotlib inline plt. figure () plt. title ( 'Relation between diameter and price') #タイトル plt. xlabel ( 'diameter') #軸ラベル plt. ylabel ( 'price') #軸ラベル plt. scatter ( x, y) #散布図の作成 plt. axis ( [ 0, 50, 0, 2500]) #表の最小値、最大値 plt. grid ( True) #grid線 plt. show () 上記のプログラムを実行すると図が出力されます。 この図をみると直径と値段には正の相関があるようにみえます。 このように、データをplotすることで回帰を行う必要があるか分かります。 では、次にscikit-learnを使って回帰を行なってみましょう。 まず、はじめにモデルを構築します。 from sklearn. linear_model import LinearRegression model = LinearRegression () model. fit ( x, y) 1行目で今回使う回帰のパッケージをimportします。 2行目では、使うモデル(回帰)を指定します。 3行目でxとyのデータを使って学習させます。 これで、回帰のモデルの完成です。 では、大きさが25cmのピザの値段はいくらになるでしょう。 このモデルをつかって予測してみましょう。 import numpy as np price = model.
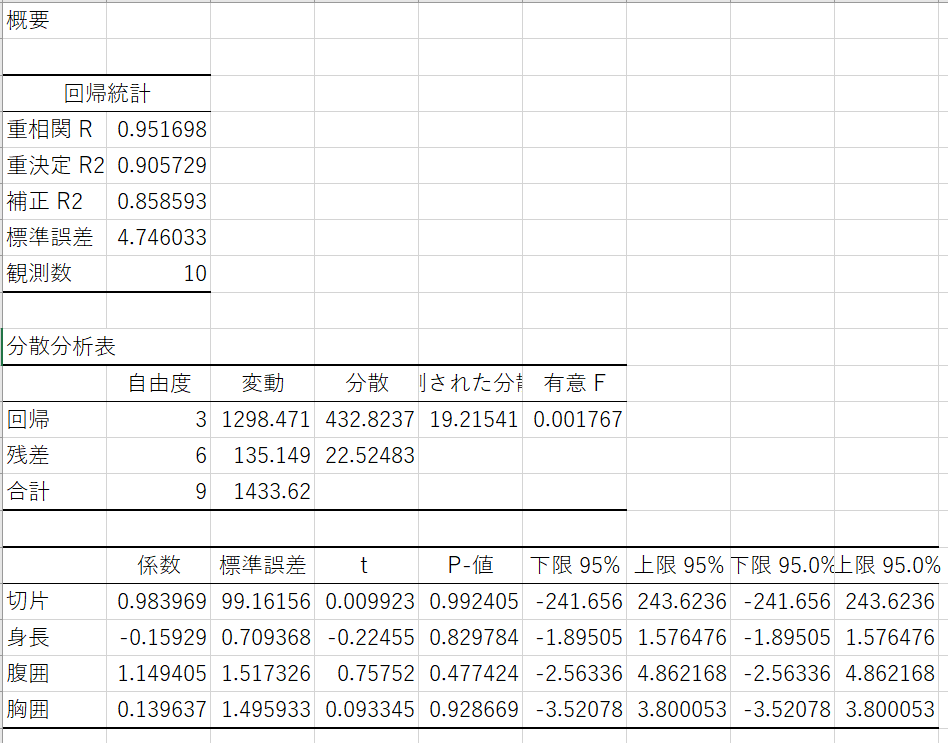
単回帰分析と重回帰分析を丁寧に解説 | デジマール株式会社|デジタルマーケティングエージェンシー
503\) \(\beta_1=18. 254\) 求めた係数から、飲み物のカロリーを脂質量で表現した式は以下のようになります。 \(y=18. 254 \times x+92. 503\) この式により、カロリーがわからず脂質のみわかる新たな飲み物があった場合、脂質からカロリーを予測できます。 決定係数とは 決定係数は、式の予測能力を表す指標 です。 式を導出した際、その式がどの程度予測に役立っているのかを、決定係数を導出して確認できます。 もしカロリーの予測時に説明変数がない場合、カロリーの平均を予測値とする方法が考えられます。 説明変数なしで平均を予測値とした場合と、説明変数に脂質量を用いて予測値を出した場合で、どれだけ二乗誤差を減少できたかの度合いが決定係数となります。 決定係数は0から1までの値を取り、1に近いほど式の予測能力が高いことを示します。 今回の例の決定係数は約0.
\[S_R = \frac{(S_{xy})^2}{S_x} \qquad β=\frac{S_{xy}}{S_x}\] ですよ! (◎`・ω・´)ゞラジャ ③実例を解いてみる 理論だけ勉強してもしょうがないので、問題を解いてみましょう 問)標本数12組のデータで、\(x\)の平均が4、平方和が15、\(y\)の平均が8、平方和が10、\(x\)と\(y\)の偏差積和が9の時、回帰による検定を有意水準5%で行い、判定が有意となったときは、回帰式を求めてね それでは早速問題を解いてみましょう。 \[S_T=S_y\qquad S_R=\frac{(S_{xy})^2}{S_x}\qquad S_E=S_T-S_R\] より、問題文から該当する値を代入すると、 \[S_T=10\qquad S_R=\frac{9×9}{15}=5. 4\qquad S_E=10-5. 4=4. 6\] 回帰による自由度\(Φ_R=1\)、残差による自由度\(Φ_E=12-2=10\) 1, 2 より、平方和と自由度がわかったので、 \[V_R=\frac{S_R}{Φ_R}=\frac{5. 4}{1}=5. 4 \qquad V_E=\frac{S_E}{Φ_E}=\frac{4. 6}{10}=0. 46\] よって分散比\(F_0\) は、 \[F_0=\frac{5. 4}{0. 4}=11. 739\] 1~3をまとめると、下表のようになります。 得られた分散比\(F_0\) に対してF検定を行うと、 \[分散比 F_0=11. 739 \qquad > \qquad F(1, 10:0. 05)=4. 96\] よって、回帰直線による変動は有意であると判定されます。 ※回帰による変動は、残差による変動より全体に与える影響が大きい \(F(1, 10:0. 05\) の値は下表を参考にしてください。 6. 回帰係数による推定を行う 「5. F検定を行う」より 回帰直線を考えることは有意 であるのと判定できました。 ですので、問題文にしたがって回帰直線を考えます。 回帰式を \(y=α+βx\) とすると、 \[α=\bar{y}-β\bar{x} \qquad β=\frac{S_{xy}}{S_x} \] より、 \[β=\frac{S_{xy}}{S_x}=\frac{9}{15}=0.
こんにちは。本日はRを使った回帰分析の方法をまとめました。 特に初心者の方はこのような疑問があるかと思います。 ✅疑問 ・回帰分析は何のために使うの? ・結果の意味はどう理解するの?